Dataset
Credit
Borrower-month observations from a credit panel, with synthetic regressors and outcome added for benchmarking.
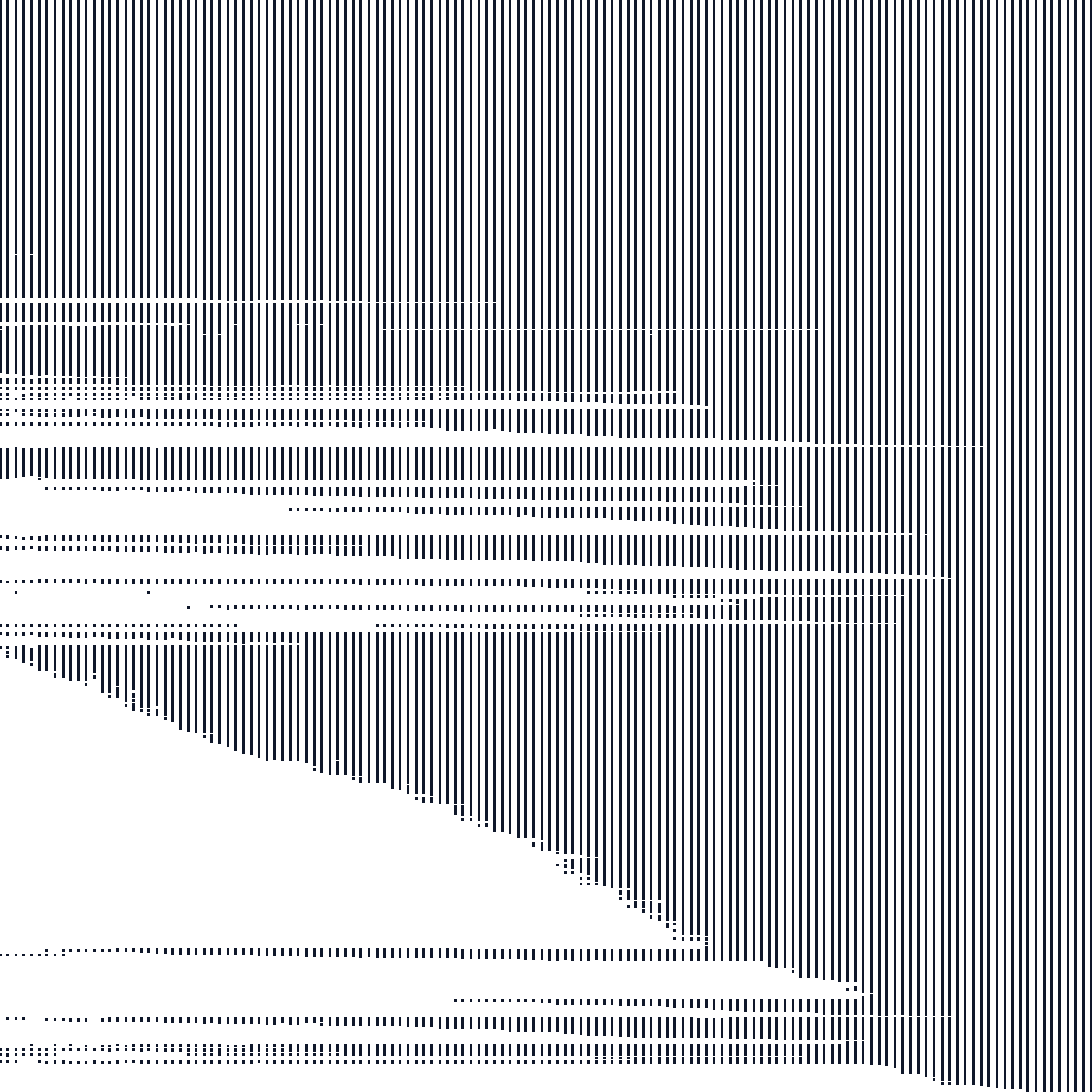
Graph Summary
A comparatively well-connected real panel; useful for baseline timing.
The primary benchmark graph is built from unique (id1, id2) pairs. The figure shows a binned sparsity pattern of the bipartite incidence block, with both partitions relabeled to contiguous integer identifiers. This block is the off-diagonal part of the corresponding graph Laplacian.
Variables
Columns in the clean CSV:
The v1 graph uses id1 and id2. Additional identifier-like columns available for richer specifications: ruc, t.
Source Notes
Borrower-period credit panel collected by the author.
Identifiers are anonymized; regressors and outcome are synthetic benchmark variables.
Historical Benchmark
2017 SEC benchmark timings for this dataset, in seconds:
| Method | Citation | Seconds |
|---|---|---|
| MAP-Aitken | (Guimaraes 2012) | 15.1 |
| MAP-SD | (Gaure 2013) | 20.5 |
| MAP-CG-Sym | (Correia 2016) | 14.2 |
| MAP+Prune | (Correia 2016) | 28.2 |
| LSMR | (Gomez 2016) | 17.3 |